 OCRFeeder fornisce in ambiente GNU/Linux una versatile e pratica interfaccia grafica ai motori OCR per il riconoscimento del testo come il famoso Tesseract OCR. In questo breve tutorial, nel quale utilizzeremo la distribuzione Ubuntu, vedremo come installare e configurare OCRFeeder ed i motori OCR Tesseract e Ocrad, quindi realizzeremo un progetto per il riconoscimento delle pagine di testo italiano e l'esportazione del documento nel formato di testo OpenDocument ODT.
OCRFeeder fornisce in ambiente GNU/Linux una versatile e pratica interfaccia grafica ai motori OCR per il riconoscimento del testo come il famoso Tesseract OCR. In questo breve tutorial, nel quale utilizzeremo la distribuzione Ubuntu, vedremo come installare e configurare OCRFeeder ed i motori OCR Tesseract e Ocrad, quindi realizzeremo un progetto per il riconoscimento delle pagine di testo italiano e l'esportazione del documento nel formato di testo OpenDocument ODT.
OCRFeeder è un software basato sull'ambiente desktop GNOME. A partire dalle immagini che riproducono le pagine di un documento cartaceo, OCRFeeder permette di definire la composizione di ciascuna pagina, individuando le aree di testo e quelle per figure, e quindi di utilizzare uno dei motori OCR (Optical Character Recognition), opportunamente configurati nella sua Libreria, per trasformare le immagini di partenza in un documento digitale con le parti di testo modificabili dall'utente.
Installare OCRFeeder e Tesseract in Ubuntu
I pacchetti di Debian e tarball sono disponibili nella sezione Download del Progetto OCRFeeder.
Per installare OCRFeeder in Ubuntu 10.10 possiamo utilizzare l'Ubuntu Software Center e cercando il pacchetto di installazione tra quelli disponibili nella Sezione di programmi per l'Ufficio.
Con l'installazione di OCRFeeder verrà automaticamente installato anche il motore OCR Tesseract per la lingua inglese al quale però bisognerà aggiungere il file dei dati Tesseract per il testo italiano; apriamo il terminale e digitiamo il comando di installazione:
Se occorre effettuare il riconoscimento del testo in altre lingue, installeremo i rispettivi pacchetti; ad esempio per lo spagnolo ed il francese installeremo i pacchetti:
~$ sudo apt-get install tesseract-ocr-fra
Per conoscere l'elenco dei pacchetti di installazione disponibili per le diverse lingue utilizzeremo il comando:
Completata l'installazione, troveremo la nuova voce OCRFeeder tra il gruppo di programmi del menù Applicazioni / Ufficio.
Configurare i motori OCR per il testo italiano e le altre lingue
Lanciamo OCRFeeder e, per prima cosa, andiamo a configurare la libreria dei motori OCR dal menu Strumenti / Libreria OCR. L'interfaccia grafica OCRFeeder, infatti, non lavora esclusivamente con Tesseract ma è in grado di utilizzare più motori OCR installati nel sistema.
Potremo, così, installare un ulteriore motore OCR, ad esempio Ocrad, dal gestore dei pacchetti Synaptic oppure dall'Ubuntu Software Center o, ancora, con la linea di comando:
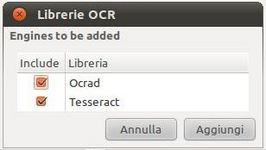 Cliccando sul pulsante Riconosci si aprirà l'elenco dei motori OCR installati nel sistema. Nella figura di esempio a fianco, sono elencati i motori Ocrad e Tesseract.
Cliccando sul pulsante Riconosci si aprirà l'elenco dei motori OCR installati nel sistema. Nella figura di esempio a fianco, sono elencati i motori Ocrad e Tesseract.
Vogliamo adesso configurare il motore Tesseract per il riconoscimento del testo italiano. Selezioniamo (con il segno di spunta) Tesseract e clicchiamo sul pulsante Aggiungi per aggiungere alla Libreria di OCR Feeder il nuovo motore che andremo a configurare per la lingua italiana.
Selezioniamo il nuovo motore Tesseract e clicchiamo sul pulsante Modifica. Nella finestra di dialogo delle impostazioni del motore OCR assegnamo il Nome "Tesseract - ITA" ed aggiungiamo l'opzione per la lingua “-l ita” alla linea dei Parametri della libreria che in tal modo diventerà:
"IMAGE $FILE -l ita; cat $FILE.txt".
OCRFeeder: Impostazioni delle Librerie dei motori OCR. |

Per aggiungere e configurare i motori OCR Tesserat per le altre lingue seguiremo lo stesso procedimento avendo cura di specificare, tra i parametri della libreria, il corretto identificativo della lingua che sarà possibile desumere dal nome pacchetto installato; ad esempio: spa= spagnolo, fra = francese; deu = tedesco, etc.
Infine, selezioniamo la voce del menù Modifica / Preferenze e dalla scheda Strumenti impostiamo come Libreria OCR predefinita la "Tesseract - ITA" che abbiamo precedentemente configurato.
Riconoscimento del testo italiano con OCRFeeder e Tesseract
Il menù File di OCRFeeder elenca le possibili alternative per caricare le immagini da sottoporre al riconoscimento del testo. Possiamo, infatti, caricare una per una le immagini (pulsante "+" sulla barra degli strumenti) oppure selezionare la cartella che le contiene tutte o, ancora, importare un documento PDF costituito da più pagine.
Tutte le pagine caricate, le impostazioni ed i riconoscimenti del testo ad esse applicate andranno a formare un Progetto OCRFeeder che, in tal modo potrà essere salvato (menu File / Salva oppure Save as...) e successivamente riaperto.
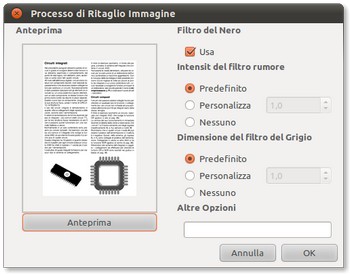 Prima di iniziare le operazioni di riconoscimento del testo è opportuno verificare la qualità delle immagini contenenti il testo. Per ottenere un buon risultato OCR è importante che le immagini siano di buona qualità con una risoluzione generalmente pari a 200 dpi (punti per pollice).
Prima di iniziare le operazioni di riconoscimento del testo è opportuno verificare la qualità delle immagini contenenti il testo. Per ottenere un buon risultato OCR è importante che le immagini siano di buona qualità con una risoluzione generalmente pari a 200 dpi (punti per pollice).
Con le lenti di ingrandimento, sulla barra degli strumenti, esaminiamo la legibilità del testo presente nelle immagini proviamo a migliorarla quanto più possibile utilizzando la funzione "Ritaglia" del menù Strumenti.
Se la pagina contiene del testo semplice senza immagini o particolari formattazioni di pagina possiamo utilizzare la funzione di "Riconoscimento Automatico" del menù Documento o dal pulsante sulla barra degli strumenti.
In alternativa, potrà risultare preferibile selezionare manualmente le singole area di Testo e le Immagini che compongono la pagina. Per selezionare ciascuna area teniamo premuto il pulsante sinistro e trasciniamo il mouse; quindi, assegnamo il Tipo di area selezionata attribuendo una delle due opzioni presenti nella colonna di destra: Testo oppure Immagine.
OCRFeeder: Layout di pagina e riconoscimento del testo. |

A questo punto non rimane che procedere con il riconoscimento del testo. Per ogni area di testo selezionata veifichiamo che il motore OCR sia il nostro "Tesseract - ITA" e clicchiamo sul pulsante OCR. Il testo riconosciuto sarà riportato nella casella di testo dalla quale potremo applicare le eventuali correzioni.
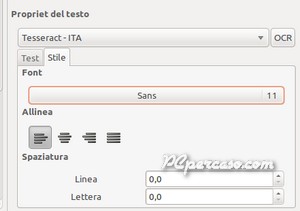
Le operazioni di riconoscimento del testo vanno eseguite per ogni singola pagina del Progetto. Dalla scheda Stile delle Proprietà del testo, nella colonna a destra, si possono applicare le proprietà grafiche che il testo assumerà nel documento di esportazione: stile e dimensione del Font, allineamento del paragrafo, interlinea e spaziatura dei caratteri.
Per definire, invece, il formato (dimensione) della pagina selezioniamo la funzione de menù Modifica / Modifica pagina dalla quale potremo selezionare un formato predefinito (A3, A4, A5, B4, etc.) oppure delle dimensioni personalizzate (Custom).
OCRFeeder: Impostazioni delle proprietà del testo. |
Non resta che esportare il risultato del riconoscimento del testo. OCRFeeder è in grado di esportare l'intero progetto o le singole pagine in HTML oppure nel formato Testo OpenDocument (ODT) gestibile quindi con le suite gratuite per l'ufficio come LibreOffice oppure OpenOffice.org.
 OCRFeeder
OCRFeeder

| Categoriatà | Produttività / Ufficio |
| Homepage | OCRFeeder - GNOME Live! |
| Licenza | GNU GPL v3 |
| S.O. | GNU/Linux |

Articoli correlati
- calibre - Oltre l'eBook reader un completo eBook manager
- LibreOffice 4.4 - Novità e installazione in Windows, GNU/Linux e Ubuntu
- PDFCreator 2 - Unire più file PDF in un unico documento
- Apache OpenOffice 4.0 - Nuova major release della suite per l'ufficio
- Calligra Suite - 9 applicazioni per l'ufficio, la grafica ed il project management
- medit - editor di testo multipiattaforma, multidocumento e multilinguaggio
- Writer2ePub - eBook in formato ePub con Writer di OpenOffice.org e LibreOffice
- OCRFeeder e Tesseract OCR - riconoscimento del testo in Linux





